

Static Code Analysis Approaches for Handling Code Quality
How to Amplify Static Code Analysis Effectiveness by Layering on Predictive Test Selection
Key Takeaways
Static analysis is an important tool in an organization’s arsenal to keep code quality up.
It can reduce code defects and improve maintainability, but can also be rife with false positives and might require multiple tools to get the coverage your organization needs.
Even with those issues, static analysis is an important aspect for any organization to deliver quality code.
By combining Predictive Test Selection with static code analysis, organizations can improve the efficiency and effectiveness of their testing process, and ensure the quality and reliability of their software.
Computer programming has come a long way since the heyday of punch cards. Gone are the days where programmers manually programmed a task by punching holes in a paper card, triple-check it for correctness, and hope that it works when they finally execute the program.


Today, developers can get feedback on a line of code’s correctness the second they type it into their code editor - a far cry from the punched card development process thanks to innovations in the field of static code analysis.
Static code analysis can identify and prevent issues early in the software development process, but not without risk of burning through resources. While static code analysis can be a valuable tool for improving the quality and reliability of software, you can increase the value by performing test impact analysis and adding in Predictive Test Selection.
Static code analysis means to analyze the source code for issues without executing it. This is in contrast to dynamic code testing, which launches the executable and verifies the correct behavior.
Static analyzers use algorithms and rulesets to identify potential issues, classify them based on severity and impact, and pass the issues along to developers to triage and resolve.
Read on to learn more about the different types of static analysis and how you can boost its effectiveness by layering on Predictive Test Selection.
Static Code Analysis Techniques Overview
Static code analysis techniques are used to identify potential problems in code before it is deployed, allowing developers to make changes and improve the quality of the software. Three techniques include syntax analysis, data and control flow analysis, and security analysis.
Syntax Analysis
Syntax analysis involves checking the code for syntax errors and coding standards violations, such as missing brackets, invalid variable names, and improper indentation.
Most modern IDEs have syntax analysis built-in. For example, Visual Studio and Visual Studio Code have code analysis built into the Intellisense feature. In the below screenshot, Visual Studio 2022 is surfacing a C# syntax error for a missing semicolon before the code has even compiled.

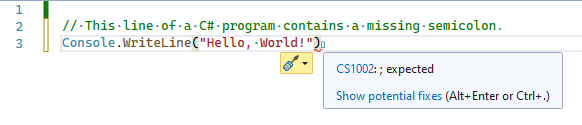
Syntax analysis helps developers catch bugs before they even hit the “run” button.
Data and Control Flow Analysis
This technique involves tracking the flow of data through the code, in order to identify potential issues such as uninitialized variables, null pointers, and data race conditions. Control flow analysis is similar and helps identify bugs like infinite loops and unreachable code.
Many modern compilers have data flow analysis and control flow analysis built-in. They surface any findings as compile-time warnings or errors. For example, the Clang toolset for the C-language family automatically performs flow analysis during compilation.
For languages that aren’t compiled, such as Python, you can manually use a data & control flow analysis tool like CodeQL.
Security Analysis
Security static analysis involves checking the code for potential security vulnerabilities, such as buffer overflows, cross-site scripting, and injection attacks. They can also scan your 3rd party dependencies for packages with known vulnerabilities and detect credentials checked into your source code.
Static application security testing (SAST) tools include:
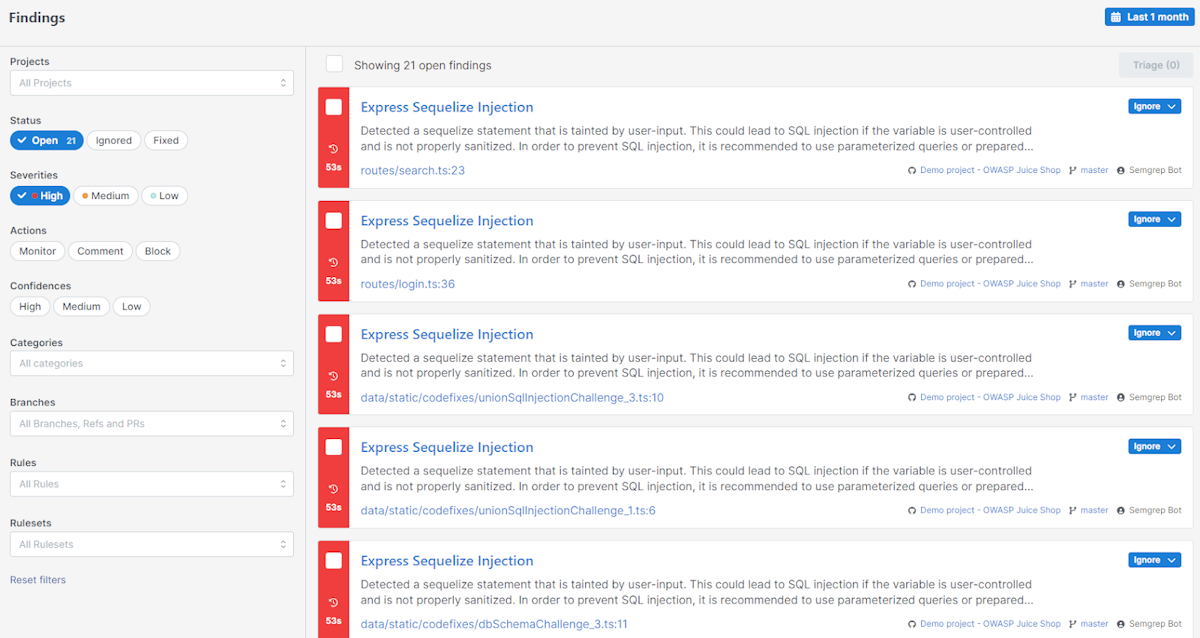
Example: Static Application Security Testing With SemGrep
SemGrep is a popular free application security static analysis tool. Running SemGrep’s security analyzer on a project with insecure code, like OWASP Juice Shop, turns up dozens of security vulnerabilities in the code.

Static Code Analysis Benefits: Quality, Prevention, Cost
Improved code quality and reliability. Static analysis augments developers by helping catch issues early. The result is better, more reliable code.
Early identification and prevention of issues. Rather than finding a bug when it already is causing customer issues, static analysis can help find them before even running the code the first time.
Increased efficiency and cost savings. No need to keep rerunning tests in your CI/CD suite if developers can catch issues early with static analysis. This saves on cloud computing costs and speeds up development cadence.
Challenges and Considerations in Using Static Code Analysis
While Static Code Analysis helps teams catch issues earlier, it is not a perfect approach and can run into false positive, false negatives, and is limited by toolsets.
False Positives
If you ask any developer what they dislike about static analysis tools, you’ll hear one answer over and over again: False positives.
Static analyzers use heuristics and rulesets to determine findings in a line of code. However, they’re not perfect and frequently turn up results that aren’t actually issues in the context.
For the following line of code example:
// Set the password policy so that user passwords expire after 365 days.
passwordExpiry = 365;An unsophisticated security static analyzer sees the string “password” and flags this as a credential in source code. Upon examination, it’s clearly not a secret and requires no code change. It requires extra dev time to investigate this issue and flag it as a false positive, which can be frustrating.
False Negatives
Software code can be complex and static analyzers might miss nuances of a situation. Therefore, you can’t rely on static analyzers to find 100% of the bugs you write.
Your cloud environment has two nearly identical server configuration files: serverprod.config (production) and servertest.config.dev(test environment).
A static analyzer is configured to scan files with the .config file extension and correctly finds issues in serverprod.config, but it misses the same issues in the servertest.config.dev file because that doesn’t match its filename pattern.
Use of multiple tools and approaches
There’s not a single static analysis tool that does it all. Many are specialized for different environments, filetypes, and types of scanning. An organization might need one tool for security scanning, a different tool for their Typescript frontend, a third tool to scan the Golang backend, and yet another static analyzer for their server configuration Terraform files. Each tool delivers value, but it can be onerous to set up and maintain all of them.
Static Code Analysis Tools
Here are some of the top tools for static code analysis:
SonarQube: a popular open-source static code analysis tool that supports a wide range of programming languages and integrates with various build and deployment tools.
Checkstyle: an open-source static code analysis tool that checks for coding style and conventions violations in Java code.
FindBugs: an open-source static code analysis tool that identifies potential issues in Java code, including performance problems, security vulnerabilities, and coding standards violations.
PMD: an open-source static code analysis tool that checks for issues in a variety of programming languages, including Java, C++, and Python.
Veracode: a commercial static code analysis tool that offers a range of features for identifying and addressing security vulnerabilities in software.
Coverity: a commercial static code analysis tool that is focused on identifying and preventing security defects in code.
ESLint: An open source project to help find and fix problems in JavaScript code. If you’re using TypeScript, check out the typescript-eslint variant.
These tools offer a range of features, support different programming languages, and have different types of software licenses. It is important to consider licensing and the specific needs and requirements of an organization when choosing a static code analysis tool.
Example: JavaScript Static Code Analysis With ESLint
Here is a simple example of JavaScript static code analysis using ESLint:

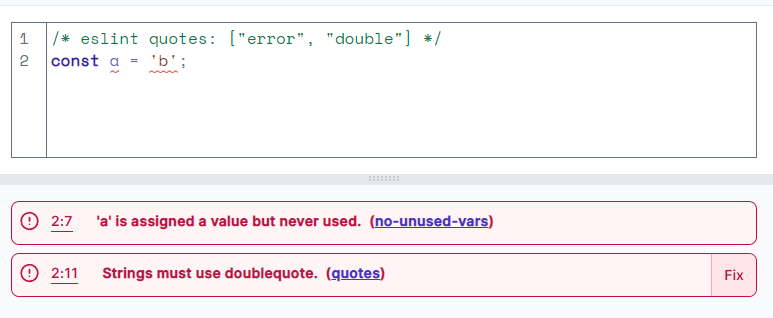
This single line of code has two issues that ESLint quickly finds:
Strings need to use double quotes
A variable is assigned a value, but is never used.
By identifying and addressing these issues through static code analysis, organizations can improve the quality and reliability of their software. Want to try ESLint yourself? You can use the ESLint Playground online.
Static Code Analysis and Predictive Test Selection
Predictive Test Selection is a technique that uses machine learning to analyze past test results and predict which tests are likely to fail in the future. This can be used in conjunction with static code analysis to improve the efficiency and effectiveness of the testing process.
Static analysis is only one facet in a software quality strategy. Most organizations use static analysis to augment their functional end-to-end software tests. Static analysis tests are only one of the types of tests that might run in a CI/CD pipeline.
One way that Predictive Test Selection can help static code analysis is by prioritizing the testing of code that is most likely to contain issues. By analyzing past test results and identifying patterns that are correlated with failure, Predictive Test Selection can help focus the testing effort on the most important or problematic areas of the code. This can help ensure that the most critical issues are identified and addressed as soon as possible, while also reducing the time and resources spent on unnecessary testing.
Overall, by combining Predictive Test Selection with static code analysis, organizations can improve the efficiency and effectiveness of their testing process, and ensure the quality and reliability of their software.
Final Thoughts
Static analysis is an important tool in an organization’s arsenal to keep code quality up. It can reduce code defects and improve maintainability, but can also be rife with false positives and might require multiple tools to get the coverage your organization needs. Even with those issues, static analysis is an important aspect for any organization to deliver quality code.
Run faster, smarter static code analysis with Predictive Test Selection. It integrates seamlessly with your CI, regardless of test type, commit frequency or branch count. Predictive Test Selection can reduce idle time by 70%. Give your developers a great experience with static analysis with intelligent testing that scales.



