










The critical challenge: testing burns through your cloud budget
Your delivery pipeline comprises of test suites a commit must pass to go to production. Every test suite run adds delay and costs to your release. This is especially true when running Selenium, UI, Mobile, and Integration tests. Often teams spend hours watching tests pass before a failure comes through—this is wasted spend.
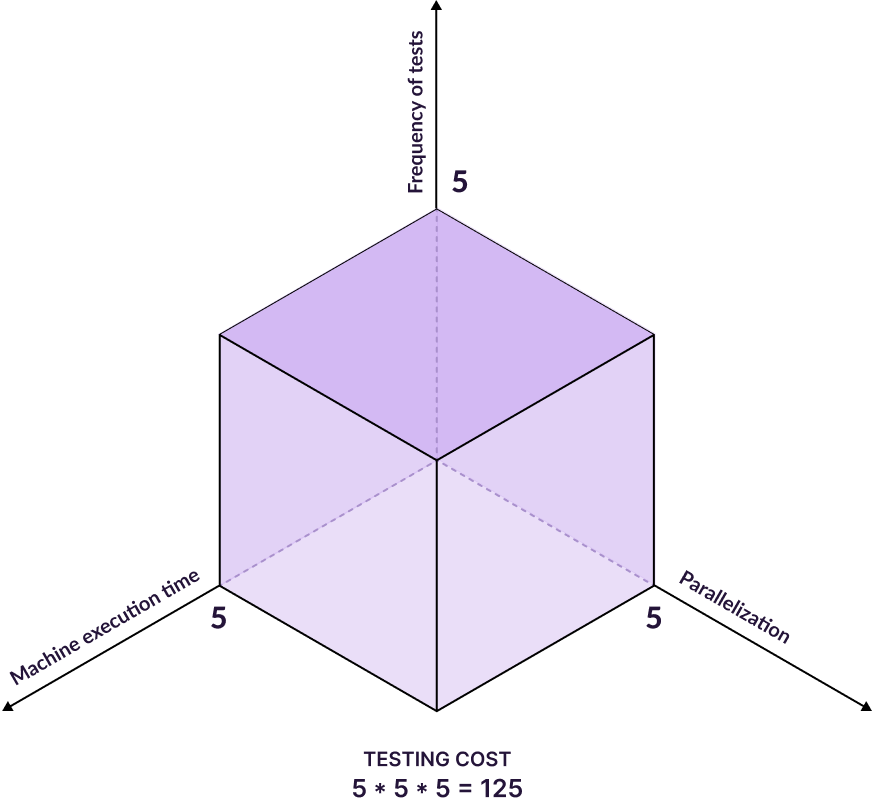
Teams can either reduce the frequency of testing or parallelization to reduce costs. But both choices result in longer feedback times and slower releases.

Solution: only run the tests which are predicted to fail
Facebook pioneered the predictive test selection approach, and Launchable's Predictive Test Selection product has made the approach turn-key and accessible to every team. Launchable’s technology uses ML to predict which tests are likely to fail in your test suite based on the commits coming in. This pragmatic risk-based approach to testing gives another dimension (test execution times) to reduce the cost of testing without impacting either quality or speed of delivery.
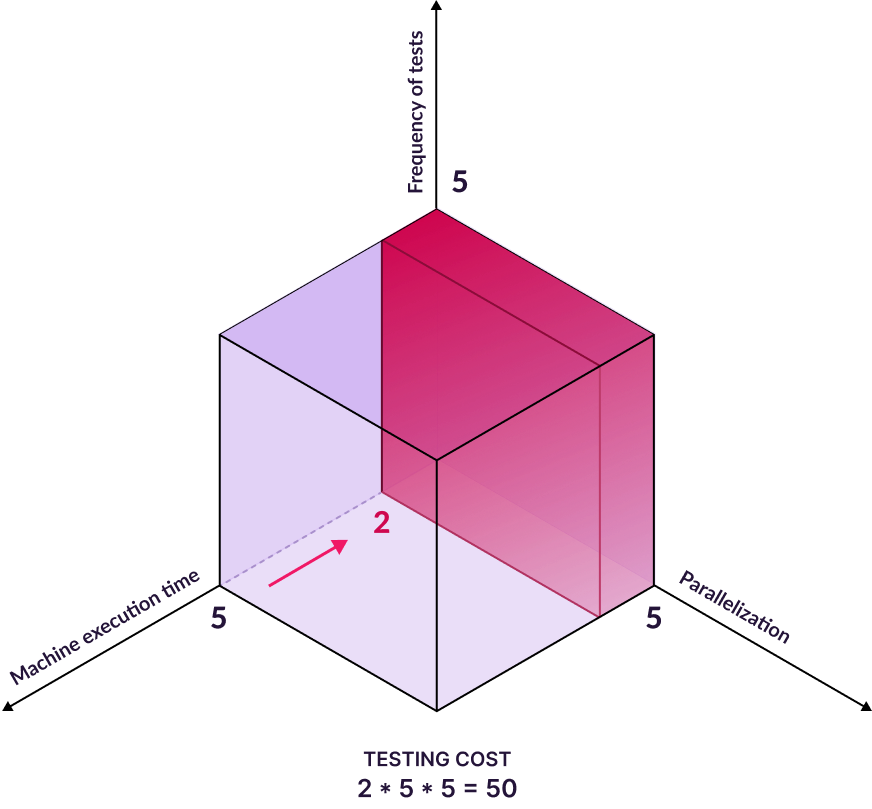
Benefit: shorter test execution times and lower cloud costs
You run the tests that are likely to fail and box them as dynamically generated subsets. Bring this approach on one or may test suites on a delivery pipeline to reduce execution times. This approach is called In-Place Shortening. See our case studies page for our massive impact for our customers.
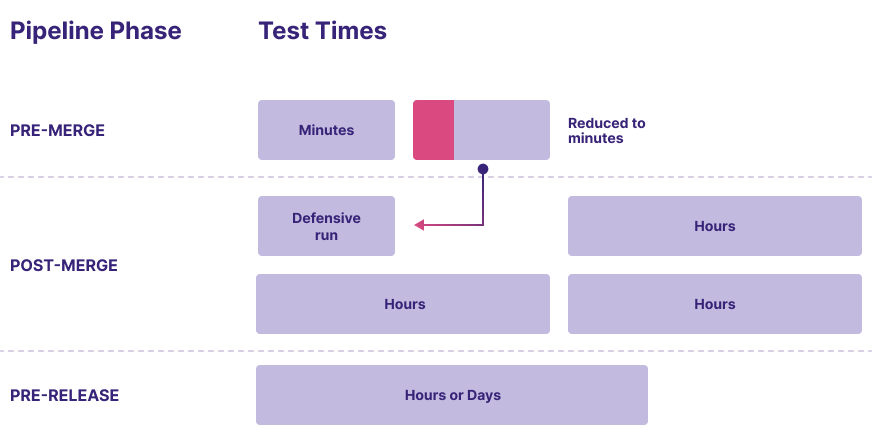
As an example in the picture below, one of the pre-merge test suites takes a while to run, delaying developer feedback and causing high infrastructure expenses. The team has started using the Launchable subset (in pink) in every pre-merge, reducing the feedback time, and running the entire test suite in post-merge, thereby reducing cloud costs.

Launchable provides a flexible approach where teams can trade off speed and costs during the application lifecycle to suit their organizational needs.
Look at how one of our customers shifted Selenium tests left to improve their feedback times drastically.
FAQs
Simply, we ask you to reduce the execution of a particular test suite wherever it is currently running (“in-place”) in the pipeline. This, as opposed to shifting a test suite left in the pipeline.
Not every test is likely to fail on a commit but we still run them because we don’t know which test would likely fail. With the advancements in AI/ML, we can now predict which tests are likely to fail with a reasonable degree of confidence. If teams are okay with the reasonable degree of confidence, you can radically reduce execution times. How significant? 40-80% is typical and sometimes even more. Sai was able to reduce 90% of execution time at 90% confidence for 75 developers. We give a dial to the teams to make a data driven decision on the trade-off between confidence and execution time.
In our opinion, testing needs to evolve to catch up to the incredible advancements in AI. The technology is ready and here now, are you?
Great question! What we are not saying is to ship bugs to production!
The answer is “it depends on your degree of risk”. For example, Sai (in the earlier use-case) was able to bring 90% reduction with 90% confidence. IOW, he was okay in letting 1/10 test failures pass because he is relatively early in the pipeline. He can do so because he has tests later in the pipeline that catch slippages.
Typically, customers do one or more of the following:
Have a defensive test run sometime later in the pipeline. This can show up as the same test suite has a “full run” later in the pipeline.
Depend on later test suites to catch with the issue. Thus, their approach is to bring this in earlier in the pipeline rather than later.
Couple this with practices like feature flags (applies to SaaS companies) such that they can rollback potential issues.
Be fairly conservative on the time/confidence ratio in the adoption phase of Launchable. For example, it is not uncommon for companies to start with something like 20-30% reduction in test times and slowly ramp that up over time.
Take the release phase into consideration in making the tradeoff. For example, for packaged software, it might be easy to be very aggressive early on and dial the tradeoff down as release approaches.
This is a complementary approach with a caveat. The caveat is that you no longer run code coverage report on every test suite run. Code coverage reports are run at a cadence that depends on what test suites are being run and what makes sense for your organization.
For example, if you optimized nightly integration test runs, you may run the code coverage report in the end of the week run.
Indeed, we are asking you to rethink testing and upgrade it in the new world of AI. Facebook and other leading companies are doing this in-house but it requires an in-house team of ML experts. A number of companies are using Launchable’s turn-key approach.
The Launchable Test Intelligence Platform also offers Test Insights to find inefficient test suites and Test Notifications to speed up feedback to developers.