










The key problem: difficult to identify Flaky tests
Most developers know there are flaky tests in their test suites that cause friction in their development cycle, but they cannot quantify the impact of these flaky tests to their management leaders. Additionally, the flakiness picture is not shared across developers—one dev might perceive the impact differently than others. Consequently, insufficient resources are allocated to fixing issues, increasing development friction.
Solution: use data to identify and assess the impact of Flaky tests
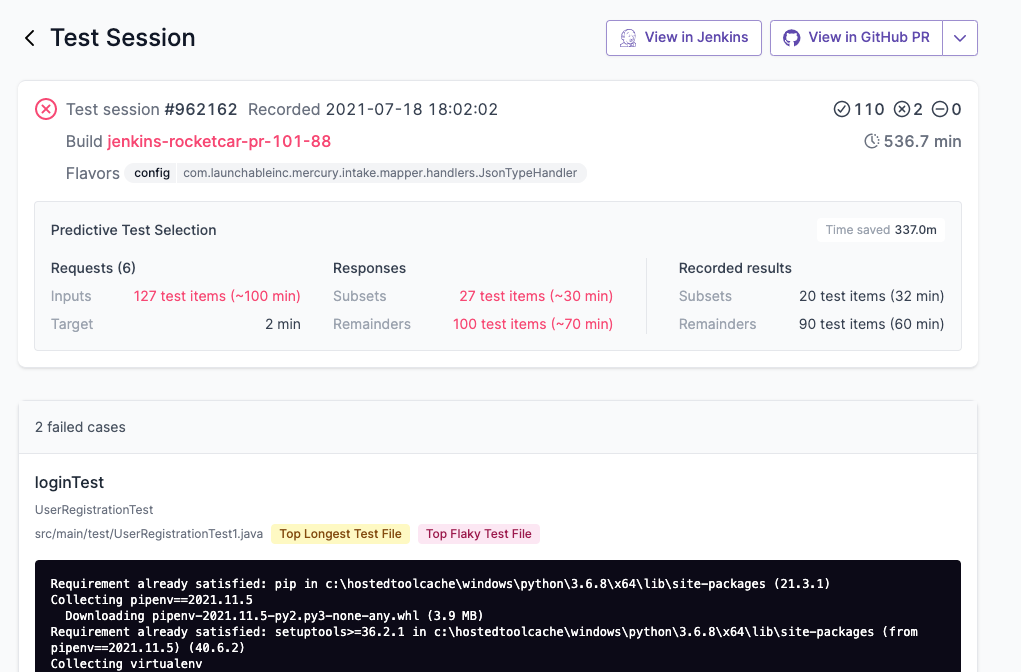
Launchable’s ML analyzes test runs to identify flaky tests in the test suite. It provides a flakiness score and the negative impact caused by the test (the number of hours of execution re-running the tests). These test sessions are re-analyzed daily to present the current information to developers.

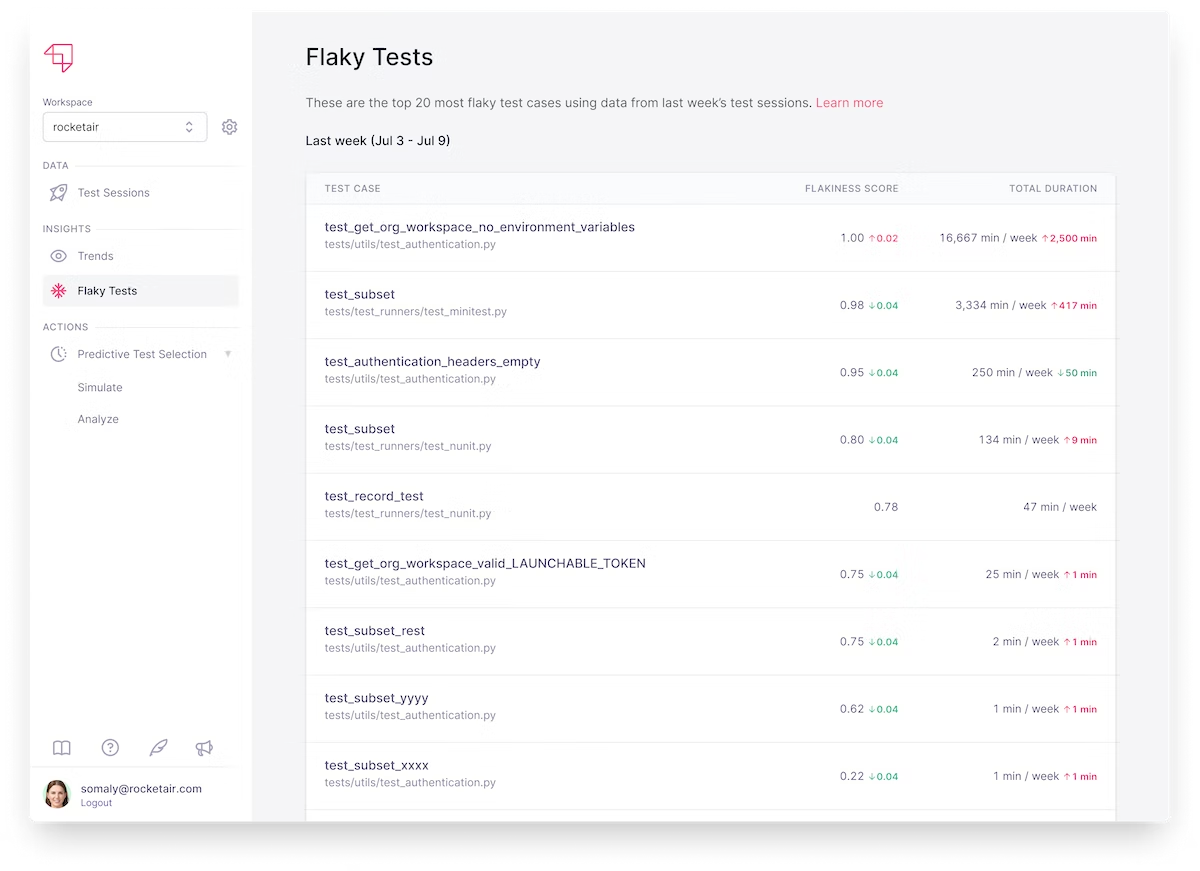
Benefit: use data to do Flaky Test Management
Devs can use this data during sprint planning to prioritize tests that need fixing, thereby improving their DevX. Launchable labels the flakiness information on test results adding another dimension and helping developers in their debugging process.

FAQs
This is a complementary approach with a caveat. The caveat is that you no longer run code coverage report on every test suite run. Code coverage reports are run at a cadence that depends on what test suites are being run and what makes sense for your organization.
For example, if you optimized nightly integration test runs, you may run the code coverage report in the end of the week run.
Indeed, we are asking you to rethink testing and upgrade it in the new world of AI. Facebook and other leading companies are doing this in-house but it requires an in-house team of ML experts. A number of companies are using Launchable’s turn-key approach.
Great question! What we are not saying is to ship bugs to production!
The answer is “it depends on your degree of risk”. For example, Sai (in the earlier use-case) was able to bring 90% reduction with 90% confidence. IOW, he was okay in letting 1/10 test failures pass because he is relatively early in the pipeline. He can do so because he has tests later in the pipeline that catch slippages.
Typically, customers do one or more of the following:
Have a defensive test run sometime later in the pipeline. This can show up as the same test suite has a “full run” later in the pipeline.
Depend on later test suites to catch with the issue. Thus, their approach is to bring this in earlier in the pipeline rather than later.
Couple this with practices like feature flags (applies to SaaS companies) such that they can rollback potential issues.
Be fairly conservative on the time/confidence ratio in the adoption phase of Launchable. For example, it is not uncommon for companies to start with something like 20-30% reduction in test times and slowly ramp that up over time.
Take the release phase into consideration in making the tradeoff. For example, for packaged software, it might be easy to be very aggressive early on and dial the tradeoff down as release approaches.
Not every test is likely to fail on a commit but we still run them because we don’t know which test would likely fail. With the advancements in AI/ML, we can now predict which tests are likely to fail with a reasonable degree of confidence. If teams are okay with the reasonable degree of confidence, you can radically reduce execution times. How significant? 40-80% is typical and sometimes even more. Sai was able to reduce 90% of execution time at 90% confidence for 75 developers. We give a dial to the teams to make a data driven decision on the trade-off between confidence and execution time.
In our opinion, testing needs to evolve to catch up to the incredible advancements in AI. The technology is ready and here now, are you?
Simply, we ask you to reduce the execution of a particular test suite wherever it is currently running (“in-place”) in the pipeline. This, as opposed to shifting a test suite left in the pipeline.
The Launchable Test Intelligence Platform also offers Test Insights to find inefficient test suites and Test Notifications to speed up feedback to developers.
Works with your existing tools, languages, and processes
Results in a week—no months-long DevOps transformations
Launchable's ML-based approach means it can work with existing languages and tools. Developers start seeing their dev cycles go faster without changing their processes.