

The Universal Guide to Regression Tests
Benefits, blunders, and best practices for regression testing, including top tools to get it right.
Key Takeaways
Regression testing re-evaluates test cases, ensuring any change in code doesn’t adversely affect other functionality and confirms that already fixed issues don’t reoccur.
Remediate running too many regression tests by selecting only necessary test cases rather than running every single one each time.
In an ideal world, software releases deploy to production and no bugs need fixing. But software development is not a perfect world. No matter how many tests you run inside your environment, bugs can still get released.
And no matter how many pre-release tests you run on a code change, there’s always a risk that it will adversely affect other parts of the software once released into the real world. Because of this reality, QA teams implement regression tests to analyze app performance after new feature releases, bug fixes, or existing feature updates.
What are regression tests, and why do you need them?
A regression test verifies that changes made to the codebase do not affect the software's functionality. Regression testing involves re-running cleared test cases against the new version to ensure the app's functionality works as intended.
To illustrate the importance of regression testing, think about how a piece of software works. As the developers create it, they make small components that work together to make an end-to-end product for the users. We could compare it to a natural ecosystem: plants and creatures working together to create balance. Each piece enables the other elements to work correctly. But, risks are involved when you introduce something new into the equation.
In our natural ecosystems, when new species of plants or animals are introduced without caution, it can harm an entire ecosystem. It doesn’t take many members of an invasive species to cause problems. Étienne Léopold Trouvelot, a French artist/astronomer, brought some insects called gypsy moths into his home. These moths escaped, and thanks to this one man and his one collection of moths, they’re now a threat to over 300 species of plants, and people in the U.S. have spent hundreds of millions of dollars trying to get them under control.
Why bring up gypsy moths? A single bad component introduced into your software can create a similar problem. No matter how insignificant a change or update might seem, it has the potential to wreck your entire software ecosystem. Regression testing re-evaluates test cases, ensuring any change in code doesn’t adversely affect other functionality and confirms that already fixed issues don’t reoccur.
Benefits of Regression Testing: Going beyond functional tests to ensure quality releases.
Regression tests fill the gap of functional tests. While functional tests check that new features work as intended, these tests aim to see if the new change works but essentially test inside a vacuum. Regression tests remedy this problem by assessing that changes and new features are compatible with the existing software by mimicking how the component functions within the real software in the real world.
Regression testing addresses new defects before they pile up and become a more significant issue for the organization. If you use regression testing early and often alongside your other tests, fixing each defect discovered by the testing is not a big deal. But suppose your team doesn’t use this testing enough or implement it at all. In that case, it will cost your organization a lot and create bottlenecks in the entire software development lifecycle.
Regression testing also ensures that your product is on the up and up over time. New releases that don’t undergo regression tests often cause more harm than help. Your team might take one step forward but then have to take two steps back from the repercussions of that change. When your team uses regression tests on any new releases, the risk of introducing new features is drastically cut. Plus, it’ll lead to a higher Customer Satisfaction Index (CSI) as your team releases new features that build on the old ones rather than causing them to break.

Common Challenges with Regression Tests: Complex, changing test suites.
As helpful as it sounds, regression testing is easier said than done. A few of the biggest challenges teams face as they implement regression tests include juggling constant requirement changes, complex testing, and growing test suites.
Constantly-changing requirements
Regression testing has to adapt alongside your software. The more you release new features, the more often the testing has to be re-evaluated. These changes cost time and money because you must run new and old regression tests. Teams often have to decide which regression tests need to run on a case-by-case basis, requiring critical thinking and expertise.
Complex testing
If your organization releases complex applications, you have to perform equally complex regression testing to ensure quality releases. Testers have complicated scenarios to develop and execute, which often take time and resources.
Massive test suites
The regression testing suite will also need to grow as your application grows in size and complexity. This large test suite could end up delaying your pipeline, causing a bottleneck, and leading to unproductivity in your development team. And in some cases, your development team might be tempted to circumvent the regression testing to meet tight release deadlines. Then, you would be back where you started: no regression testing with all the risk.
Luckily, there are ways to solve these problems. Mainly, intelligently paring down your entire testing suite – including regression testing and other types of tests such as unit testing and functional testing – can make your testing process more efficient and reduce noise and developer frustration.
Retesting vs. Regression Testing
Regression testing is sometimes confused with retesting, but they serve two different purposes. Retesting is for a targeted reason; testers use it to dig deeper into a particular problem. Retests are not automated or on a regular cadence. Instead, they get used on an as-needed basis for identifying what’s wrong inside a failed test case or for re-checking something after it was corrected to ensure that the bug actually got fixed.
Regression testing, on the other hand, is a regular, cadenced practice, often done with automation. It focuses on passed test cases because it’s a checkpoint for code that’s on its way to release.
The two test types can run parallel since they handle the two different outcomes that a code snippet could have (either passing previous tests or failing them).
When to Apply Regression Testing
Since regression testing ensures that a code change or update does not create a domino effect on the other software parts, run them early and often. Regression testing usually needs to happen after the following steps in your SDLC:
A new requirement is put onto a feature that already existed
A new feature/function gets implemented
Your team decides to alter the codebase to fix defects
The source code gets optimized to make performance improvements
A patch is released
The software configuration gets changed
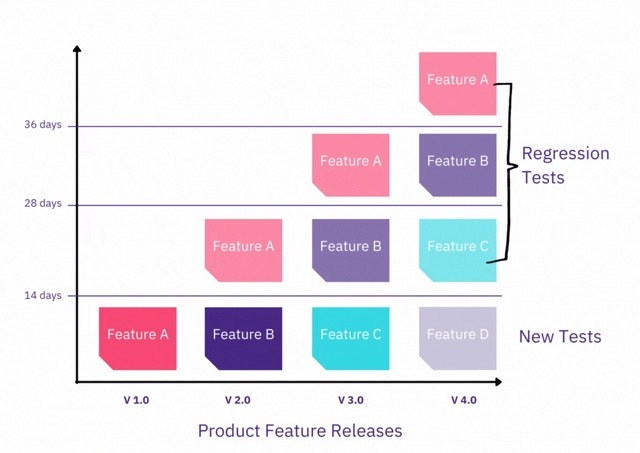
Selecting test cases for regression tests
Remediate running too many regression tests by selecting only necessary test cases rather than running every single one each time. Prioritize testing the following types of changes, components, and updates first:
Areas of the software that experience frequent defects
The most visible, critical user-facing functions inside your application
Functions that verify core features of the product
Any functionalities that just underwent changes
Plus, it’s also a great idea to run integration and complex test cases, boundary value test cases, and a sample of succeeded and failed test cases.
How to Perform Regression Tests
Depending on your specific organizational needs, regression testing practices can vary but typically include these five common steps.

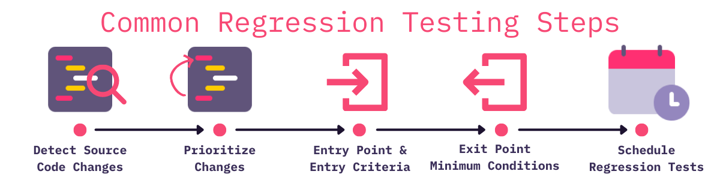
Detect Source Code Changes: Scan the source code for changes and optimizations, and identify the modified components and the impact on existing features.
Prioritize Changes: Prioritize these changes and product requirements in order to optimize the testing pipeline and the test cases.
Entry Point and Criteria: Assess if your app meets entry point and entry criteria eligibility.
Exit Point: Identify the exit point for the mandatory minimum conditions from the entry point and entry criteria.
Schedule Regression Tests: Confirm all test components and schedule the execution time.
Regression Testing Tools
Regression tests work best when automated and tailored to match your unique SDLC. Luckily, the software development industry has a plethora of automated regression testing tools out there! Here are a few of our favorites:
Selenium - An open-source web automation solution. Selenium WebDriver enables users to create robust, browser-based regression automation suites and tests and scale and distribute scripts across many environments. It’s ultimately a collection of language-specific bindings created to “test drive” a browser natively.
Launchable - 👋 Yes, that’s us! Our dev intelligence platform helps developers speed up their testing suites, including regression testing. We specialize in making test suites more reliable and efficient, creating a better experience for your entire development team.
Watir - Powered by Selenium, Watir is an open-source Ruby library for automating tests. It interacts with a browser like people: clicking links, filling out forms, and validating text.
Serenity - An open-source library that helps you write higher-quality automated acceptance tests faster with reporting and mapping capabilities.
Katalon - Focuses on automating testing in general. It includes several flexible options for scaling and customizing your test automation. Plus, it integrates with CI/CD pipelines and agile development cycles.
Launch Fearlessly with Smarter Regression Testing through Predictive Test Selection
While test automation solutions like Selenium and Watir are helpful for building your test suite, organizations can still run into an all too common velocity bottleneck: inefficient testing. Launchable helps development teams identify and run tests with the highest probability of failing based on your code and test metadata to speed up the dev feedback loop.
Rather than requiring your developers to run your whole test suite, Launchable’s Predictive Test Selection uses ML to intelligently choose the best tests to run and help you weed out the tests that consistently don’t work. Launch your new features fearlessly with smarter regression tests with Launchable.



