

Regression Testing in Software Engineering
Test types, processes, and approaches to regression testing for better software engineering.
Key Takeaways
Regression testing prevents software regression by verifying that any code changes don’t impact the existing functionality of the product.
Regression testing usually takes four steps to complete: bug identification, changing source code, test case selection and execution options, and prioritization of test cases.
Learn how to automate your test regression selection with data-driven insights to speed up software engineering.
At one time or another, most software engineering teams have found themselves in the middle of an unexpected domino effect caused by software regression. One seemingly isolated change can cause giant repercussions on existing functionality if not effectively checked.
When a team releases updates into the wild without understanding what those releases could do to existing functionality, there’s a good chance that these new updates will cause adverse effects on user experience and developer productivity. And recovering from these unexpected results might feel like being chased by a boulder!
Regression testing in software engineering prevents this by verifying that any code changes don’t impact the existing functionality of the product.


When to do regression testing?
The value of regression testing is finding whether components are impacted by any modifications. To succeed, regression testing needs to be done after most types of changes, especially when:
New functionality gets introduced to the software
The team finds a defect and debugs it (regression testing ensures that the debugging process doesn’t cause even more problems!)
The code is optimized to function better
An aspect of the existing development environments gets changed
Regression testing needs to follow some sort of cadence to ensure that it’s executed at the correct times. For example, if a big project is being completed over several months, it’s generally a good idea for teams to perform regression testing daily. But for minor weekly releases, teams should perform regression testing on a cadence after they complete routine functional tests.
Types of Regression Testing in Software Engineering
Because regression testing looks different in different situations, engineers should look at the three main types of regression testing and decide which is best for each stage of their development process.
Unit regression testing
Unit testing focuses on assessing isolated units of source code. Unit regression testing falls under this category because it focuses on single pieces of code by testing them in isolation. Running alongside other unit tests, the main goal of unit regression testing is to identify exactly which repercussions will happen once the unit in question interacts with the rest of the software components.
Partial regression testing
Partial regression testing simply verifies that the code is operating correctly after a change has been released and integrated with the rest of the software. This type of regression testing is specifically intended for small changes pushed to existing software.
Complete regression testing
Complete regression testing means that regression tests are added to all existing test suites. It’s performed when significant changes get pushed into the root code of your software. This type of regression testing also helps software engineering teams get a baseline understanding of which other components are affected by this big change.
Four Standard Steps for Regression Testing
Regression testing usually takes four steps to complete: bug identification, changing of source code, test case selection and execution options, and prioritization of test cases.
1. Identification of bugs
Before your team executes regression tests, performing other functionality tests and identifying any bugs is essential. This prevents any underlying functionality problems from carrying over.
2. Modifications of source code
After identifying bugs, teams should take steps to debug and modify the source code, making it as bug-free and clean as possible. This will ensure that your regression testing process is straightforward and focused, making it less costly and time-intensive.
3. Selection & execution of test cases
After debugging your code, it’s time to select and execute suitable regression test cases. Over time, a software engineering team will compile a list of tried-and-true tests they can run whenever certain areas of the software get modified. But, these tests will also need to be updated, changed, or added to, depending on other changes happening across the entire software lifecycle.
There are a few different techniques for selecting which existing tests should be run, along with deciding whether or not to generate new ones, including:
All test cases. This technique means a team executes all existing test cases within their test suite. While it might seem like the most reliable option, it’s also the most time-consuming and costly choice, as some teams might have huge test suites that could take hours, or even days, to run. It also creates lots of unnecessary noise within your software pipeline.
Random selection. Some teams randomly select test cases to run against their code changes. While a good idea, in theory, random selection will only work if all tests are equally good at detecting faults. This is often not the case!
Modification. To execute this technique, teams only run the test cases relevant to the source code's modified parts and their dependencies. While this might be the most cost-effective choice, it takes a lot of critical thinking and expertise to pick the correct test cases.
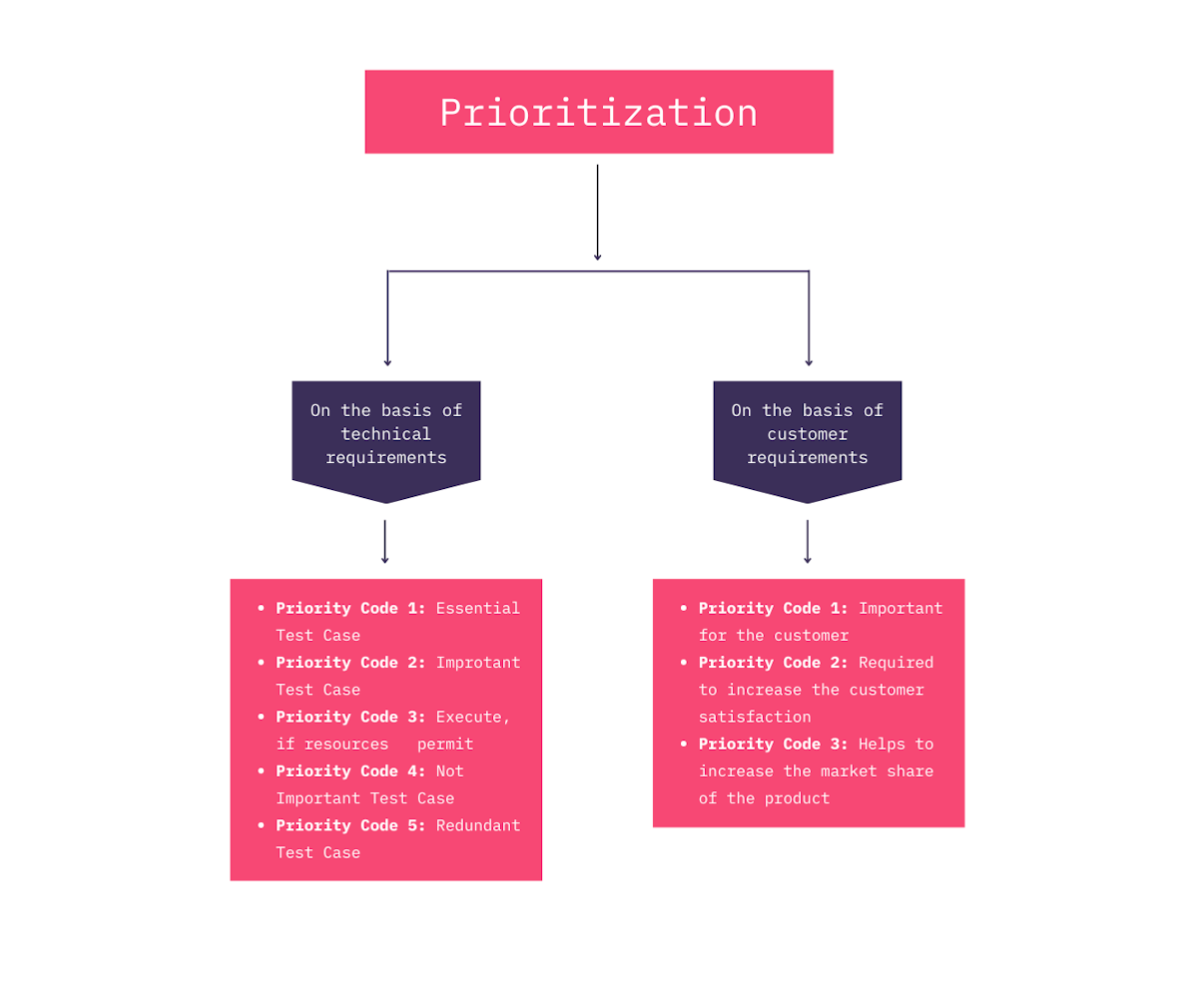
4. Prioritization of test cases
After choosing a method for selecting and executing test cases, most teams will prioritize the test cases, either based on technical or customer requirements. To do this, teams need to thoroughly understand which tests are the most reliable and applicable to each change. Prioritizing test cases takes a deep understanding of your team’s existing test suites.

Benefits and Challenges of Regression Testing
Regression testing, as we’ve seen, can reap tons of benefits for software engineering teams. Nowadays, it’s no longer a question of “should our team do this,” but more about “how do we do this in a way that works with our development lifecycle.” The repercussions of not executing regression tests can be detrimental.
Imagine pushing a change to your software, only to realize that it caused the existing application to crash and burn. The panic and confusion following this event could cost a lot: resources, customer satisfaction, team productivity, brand reputation, and more.
Instead of blindly hoping for the best with every new code change and possibly suffering the consequences if it doesn’t work out, your team can use regression testing to ensure that any new components will play well with the others. In the end, it facilitates better quality and functionality for your software.
Some teams might hesitate to add regression testing to their test cycles because it can be challenging. Many of today’s software engineering frameworks - Continuous Integration and Continuous Delivery/Continuous Deployment or DevOps - are built on an early testing foundation. It is often still hard to implement because all test suites, including regression testing, must be fundamentally understood and monitored by teams.
As we saw through the process of regression testing, a team needs to understand its test suites deeply. Otherwise, they won’t run the right tests at the right time, possibly leading to longer testing cycles and less developer productivity.
However, this type of deep knowledge about your test suites is challenging to achieve. It requires intelligence on the accuracy and function of each test. And it requires staying on top of changes in test quality because, unfortunately, even the best tests will decrease in quality over time, becoming flaky and unreliable.
The best way to overcome these hurdles is by automating your test selection with data-driven insights.
Intelligently Select Your Regression Test Subsets with Launchable
Our team at Launchable saw how overwhelmed software engineering teams were getting as they manually selected test cases. So, we decided to create an AI-powered platform for test automation.
Instead of running your entire test suite – which wastes time and costs – or using up resources to manually pick test cases for every situation, Launchable’s Predictive Test Selection automatically selects the best tests for each condition and runs them within minutes.
We also offer tools for monitoring your test entropy, enabling you to see gaps where you might need to add new tests or retire old ones. Learn more about how Launchable’s machine learning platform can help you intelligently select regression test subsets today.



